

推荐单位:中国科学院
申报单位:中国科学院计算机网络信息中心、中国科学院动物研究所
一、背景
传统单细胞库物种单一、标准各异,阻碍跨物种大模型训练,亟需建设高标准、跨物种、AI-Ready数据集。中国科学院计算机网络信息中心与动物所共建亿级多物种单细胞转录组AI数据集scCompass,严选自全球主流数据库,经统一质控、归一化与注释,集成人、小鼠等13个关键物种超1.04亿单细胞,为跨物种生命规律解析与大模型训练提供核心数据基座。
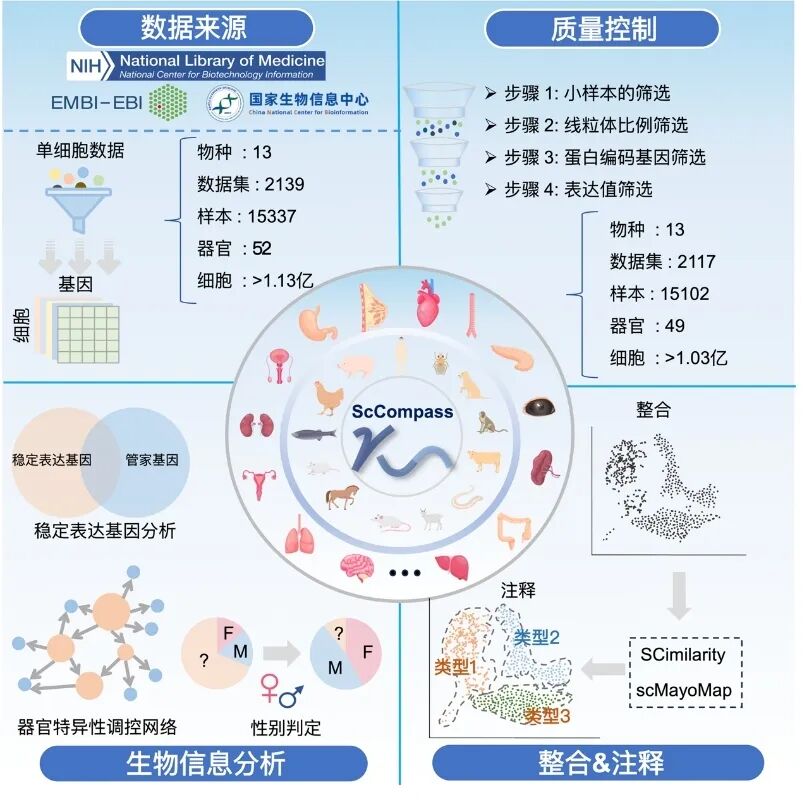
scCompass建设框架图
二、方案和成效
一是建设覆盖全面的多物种大规模单细胞转录组数据集。scCompass通过高一致性流程整合全球权威数据源,实现整合跨物种13个典型模式生物,覆盖发育、疾病等关键场景;对PB级原始单细胞转录组实现全流程标准化,形成统一分析流程;最终集成亿级多物种转录组AI高质量数据,包含1.04亿单细胞。
二是面向模型需求,提供多尺度高精度注释数据集。深度整合主流单细胞基础模型对数据结构、预处理等标准,面向大模型需求涵盖不同规模、不同格式的“即取即用”训练数据集与支持模型的预训练检查点,在多个SOTA模型验证有效性。
三是建设开放共享配套平台。支持按物种、器官、样本等多维筛选数据,支持全景挖掘稳定表达基因与器官特异基因,集成在线归一化、注释、性别较正及基因特异性可视化工具,降低生信与AI研究门槛。
四是支撑领域应用。自2025年5月公开发表于Advanced Science以来,已服务37个国家/地区,支撑国际上首个知识与数据联合驱动的亿级参数、多物种生命基础大模型GeneCompass以及细胞图基础模型CGCompass,并支撑XCompass生命科学智能数字细胞基础大模型赋能细胞治疗。
三、创新点
一是立足领域需求,解决现有数据库覆盖狭窄、流程不统一等问题。采用高一致性流程整合全球权威数据源,实现跨物种包括13个典型模式生物,进行全流程标准化,形成统一原始数据质控、基因表达归一化、高精度细胞注释流程,构建亿级单细胞转录组高质量数据。
二是突破传统数据库非AI友好的局限。深度适配基础模型开发需求,提供预对齐主流模型输入标准的分规模数据集;内置预训练模型检查点,并进行下游任务细胞注释、基因互作评测;在跨组织注释等任务中,模型训练效率和准确率超越现有数据库。

全国数据标准化技术委员会 版权所有 ©2009-2025
地址:北京市东城区安定门东大街1号 中国电子技术标准化研究院
联系电话:010-64102858 传真:010-64102861 邮编:100007


 京公网安备11010102004561号
京公网安备11010102004561号